Compare, Contrast, and Evolve: A Data Quality Literature Review
A survey of how data quality has been defined, measured, and debated across decades of research — and why the field still lacks the practical, quantitative foundation modern AI demands.
As data drives more and more of business, politics, and personal lives, understanding the quality of data is increasingly critical. But as an area of research, DQ has not received the attention it deserves. Decades into its development, the field is still finding its footing. Schools of thought are not clearly defined (Figure 4.1). Basic definitions lack clear agreement. For an inherently applied topic, very little quantitative research has been put forth. Part of this is due to timing. In 1996, Wang and Strong (1996) published their seminal paper “Beyond Accuracy: What Data Quality Means to Data Consumers.”1 They defined data quality as ”data that are fit for use by data consumers.”2 Within a few short years, the nature of who uses data, how we use data, and how that data is built changed dramatically. From the rise of big data to the data science revolution to ChatGPT, the world of data has kept on evolving in the decades since. Timing is not the only culprit. A lack of concrete examples and quantitative clarity have hindered progress. Theory has dominated research into this incredibly practical and applied topic. Few papers explore specific problems to be solved or datasets to be investigated.3 The lack of specific, particular applications has slowed adoption and, as a result, development of the field.
This paper has influenced much of the subsequent work in data quality and has been cited over 3,000 times according to ResearchGate.com. In this field, that is a very notable number of citations.
Figure 4.1 (adapted). Varying Approaches in Big Data Quality Research A selection from Ramasamy and Chowdhury, 2020’s overview of big data quality literature and the lack of agreement therein.
| Research Work | Structure | Terms used in relation to dimensions |
|---|---|---|
| Big Data Quality: A Quality Dimensions Evaluation (Taleb et al., 2016) | 3 Dimensions | Accuracy, Completeness, Consistency |
| Big Data Quality: A Survey (Taleb et al., 2018) | 4 Categories, 18 Dimensions | Intrinsic: Accuracy, Timeliness, Consistency, Completeness. Contextual: Reputation, Relevancy, Accessibility, Quantity, Value-added, Believability. Representational: Interpretability, Representational, Conciseness of representation, Consistency, Manipulability, Ease of understanding. Accessibility: Access, Security |
| Big Data Validation Case Study (Xie et al., 2017) | 4 Dimensions | Validity, Completeness, Consistency, Accuracy |
| Big Data, Big Data Quality Problem (Becker et al., 2015) | 7 Dimensions | Accuracy, Precision, Completeness, Consistency, Timeliness, Lineage/Pedigree and Relevance |
| Context-aware data quality assessment for big data (Ardagna et al., 2018) | 7 Dimensions | Accuracy, Completeness, Consistency, Distinctness, Precision, Timeliness, Volume |
| Data quality assessment: The Hybrid Approach (Woodall et al., 2013) | 2 Dimensions | Completeness, Accuracy |
| Data quality for data science, predictive analytics, and big data in supply chain management (Hazen et al., 2014) | 2 Categories, 4 Dimensions | Contextual: Accuracy. Intrinsic: Timeliness, Completeness, Consistency |
| Data quality in big data processing: Issues, solutions and open problems (Zhang et al., 2017) | 4 Dimensions | Availability, Usability, Reliability, Relevance |
| Data Quality Issues in Big Data (Rao et al., 2015) | 5 Dimensions | Accuracy, Confidentiality, Completeness, Volume, Timeliness |
| Data quality management, data usage experience and acquisition intention of big data analytics (Kwon et al., 2014) | 2 Dimensions | Consistency, Completeness |
But there is a cultural component, too. People often assume, without proof, that modern data is high quality data.
Well-formatted and stored in vast databases, modern data certainly looks the part. Given its size, speed and societal gravitas, it can easily intimidate those who would question it. Data quality professional and author Laura Sebastian-Coleman stated it well: Living in the Information Age, we are influenced by prevailing assumptions about data—that it simply exists out there waiting to be used (or misused) and that it represents reality in a true and simple way.(Sebastian-Coleman, 2013)
Xiao-Li Meng, Founding Editor-in-Chief of the Harvard Data Science Review, commented on this tacit belief about modern data: ”It is…wishful thinking to rely on the ’bigness’ of Big Data to protect us from its questionable quality, especially for large populations” (Meng, 2018). Whether we assume, wish, or simply refuse to look, the quality of data is what it is. And whatever it is, it determines that data’s suitability for use. As many have noted, data quality is particular to the application. Without a specific example, the problem itself is broad and nebulous. It may even seem that data quality is a goal in and of itself. If it is a goal in its own right, it is a spiritual goal, not a practical one. Yet data quality is an utterly practical need. To meet the practical needs of data quality, we will need to bring sharp detail to the inchoate discussion of data quality. We need clarity, specifics, and measurement.
Perspectives on Data
Data has both producers and consumers, both a cost and value (Wang and Strong, 1996; Karr, Sanil, and Banks, 2005). A data producer is a person or group involved in the data production process. A data consumer is a person or group that relies on the data to drive decisions, conduct analysis, or build models. Each has a perspective on data quality. Which perspective is taken influences a researcher’s approach. Different researchers have treated data as a product, a service, and the output of a production process (Kahn, Strong, and Wang, 2002; Wijnhoven et al., 2007). A product view of data quality focuses on the desired attribute of the data. The service approach views data as a deed performed by one for another. A production approach, of course, considers how the data is made. The lens through which data is viewed influences how its quality is measured and managed. Many authors take a mixed approach, but only a few remark on the distinction. For our part, we view data as both a product to be consumed and an output of a production process. The latter drove our efforts to understand how the data was made (Chapter 2). The former will inspire us to specify actual use cases (Chapter 5) for which we will evaluate our data (Chapter 6, Chapter 7).
Approaches
Data quality was originally a concern primarily of the data producers. That changed when Wang and Strong (1996) expanded on the definition of DQ from
”fitness for use” and defined it to be ”data that are fit for use by data consumers.” Of course, producer DQ did not fall away. Papers like Serhani et al. (2016) still focus on data engineering concerns. Other research focuses directly on the usability of data, like Meng (2018). More often, data quality has been pursued with one foot in each of the producer and consumer camps. This has lead to research that explicitly considers the process behind the data and the user of it, like Karr, Sanil, and Banks (2005). Usually the dual focus is implicit, with papers including dimensions like security and relevancy4 side-by-side. Both production and consumption of data have evolved tremendously since Wang and Strong’s 1996 paper. The DQ needs of each have evolved as well. Research into data quality has struggled to keep up (Taleb, Serhani, and Dssouli, 2018; Rao, Gudivada, and Raghavan, 2015; Cai and Zhu, 2015). The disciplines of computer science, total quality management, and statistics have all contributed significantly to the broad concept of data quality (Karr, Sanil, and Banks, 2005). But, it has not been enough. As Meng (2018) and many others have observed, big data brought new challenges to data quality. Both academic research and actual application have begun to rely heavily on big data and subsequently are vulnerable to its shortcomings. In order to realize the value that so many believe big data will deliver, much more practical, coordinated, and cross-disciplinary work is needed.
E.g. Pipino, Lee, and Wang (2002).

Figure 4.2 (redrawn). ”A Conceptual Framework of Data Quality” from Wang and Strong (1996) shows one of many frameworks proposed for DQ over the past three decades.
Frameworks
Many authors have proposed frameworks to organize DQ dimensions and metrics. The designs vary widely. Some are more complicated than others but all demonstrate different perspectives on what data is and how it should be managed. Wang and Strong (1996) group DQ dimensions into intrinsic, contextual, representational, and accessibility categories (Figure 4.2). Despite sharing authors, Kahn, Strong, and Wang (2002) propose an alternative and quite divergent categorization. They divided data quality dimensions into quadrants of sound information, useful information, dependable information, and usable information (Figure 4.3).5 This organization reflects the vision of data as both a product
Although more recently information has been distinguished from data, at the time of Kahn, Strong, and Wang (2002) the terms data and information were often used interchangeably (Pipino, Lee, and Wang, 2002).

Figure 4.3 (redrawn). Product and Service Performance Model for Information Quality (PSP/IQ) is a framework from Kahn, Strong, and Wang (2002) that includes less common approaches to DQ, including sound, dependable, useful, and usable information.

Figure 4.4 (redrawn). Two-Layer Framework for DQ from Cai and Zhu (2015) is presented as a ”universal” standard for assessment by the authors. and a service whereas the previous one embodies the consumer-centric view of data quality. Some frameworks are blunt in the reasons underlying their categorization. Karr, Sanil, and Banks (2005) group dimensions into hyperdimensions of process, data, and user. ”Process” refers to the production and engineering, ”data” includes dimensions like completeness and accuracy, and ”user” collects the di-
mensions that data consumers are impacted by, like interpretability and relevance (and, unsurprisingly, timeliness). Pipino, Lee, and Wang (2002) partition data quality metrics into task-dependent and task-independent. The former includes government regulation, business rules, and other constraints that are specific to the application. Task-independent metrics can be applied to any data set, regardless of application. Some frameworks have finer-grained divisions. Cai and Zhu (2015) categorize dimensions into five groups (Figure 4.4). They build out their framework further, defining elements contained in those dimensions and indicators within the elements. Zaveri et al. (2015) recognize seven categories of data quality: content based, context based, rating based, accessibility, intrinsic, contextual, and representation. Regardless of the framework used, the organization is mostly superficial. The dimensions may share names, but often what those names represent is not agreed upon.
Dimensions
As see in Figure 4.1 and discussed already, the dimensions of data quality are still being sorted out (Ramasamy and Chowdhury, 2020; Batini et al., 2009). Even if they were codified, it wouldn’t align researchers. It’s not only which dimensions to include that is unclear. The definitions of those dimensions are not agreed upon (Batini et al., 2009). The list of data quality dimensions was once extensive. Wang and Strong
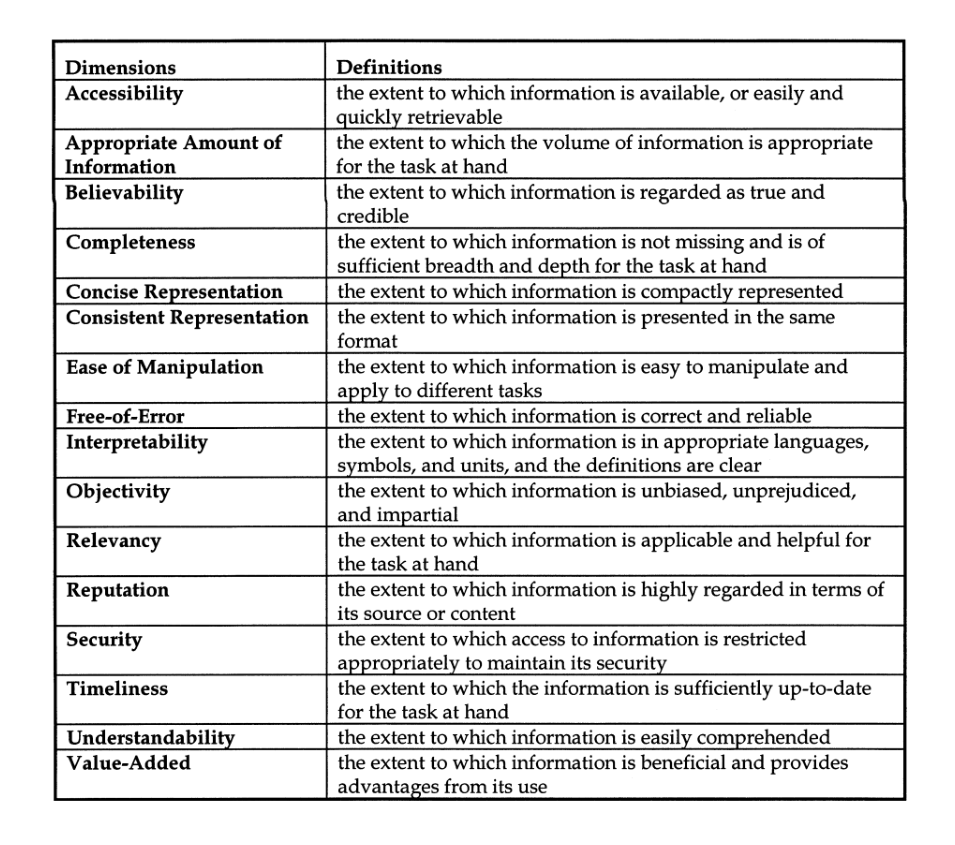
Figure 4.5. An Example of DQ Dimensions Definitions Sharing authors and citations can help align definitions. These data quality dimensions from Kahn, Strong, and Wang (2002), cited as sourced from Wang and Strong (1996), are later cited by Pipino, Lee, and Wang (2002). (1996) provided 20 data quality dimensions. Kahn, Strong, and Wang, 2002, sharing authors and directly referencing the that research, reduced the number of dimensions to 16. Karr, Sanil, and Banks (2005) enumerated 15 dimensions. In subsequent years, fewer dimensions have been considered. In the research we reviewed, accuracy, completeness, and timeliness were some of the most popular among the many proffered. When authors have expanded the list, the additional dimensions can be
rather scattered. For example, Abdullah et al. (2015) asserts that high quality data is data that is available. Hartig and Zhao (2009) and Juddoo (2015) emphasize the importance of believability to quality. Serhani et al. (2016) include consistency in their list. Ardagna et al. (2018) add not only consistency but also distinctness, precision, and volume. Ramasamy and Chowdhury (2020) expand their list of commonly used dimensions with consistency, validity, and uniqueness. Definitions align as often as they deviate. The most aberrant definitions are provided by Cai and Zhu (2015). Conflicting definitions, of course, can lead to different metrics with which to measure them (Pipino, Lee, and Wang, 2002). Although, as we’ll see, an abundance of metrics is not a concern.
Accuracy
In Wang and Strong (1996), accuracy was defined as ”the extent to which data are correct, reliable, and certified free of error.” Since then, accuracy’s definition has largely fallen into two camps: closeness to the real-world or falling within an expected domain. The first camp includes Serhani et al. (2016) and Ramasamy and Chowdhury (2020), who define accuracy in terms of how closely data represents the realworld. Zaveri et al. (2015) define semantic accuracy as ”the degree to which data values correctly represent the real world facts.” Cai and Zhu (2015), Karr, Sanil, and Banks (2005), and Abdullah et al. (2015) similarly connect accuracy with reality or a source of truth. Karr, Sanil, and Banks (2005) explicitly consider accuracy a binary problem. Cai and Zhu (2015), Karr, Sanil, and Banks (2005),
and Meng (2018) reflect on the common impracticality of finding a reference value against which to compare a value’s accuracy.6 Ardagna et al. (2018) refers to Wang and Strong (1996)’s definition of accuracy, but in application they evaluate accuracy according to a value’s inclusion in an expected interval. Batini et al. (2009) assert that data quality methodologies only consider syntactic accuracy. They define syntactic accuracy as closeness to the definition domain, xi ∈ X rather than xi = f (i) ∈ X.
Measurement error is of interest to statistics, psychology, economics, and most fields that rely on data. It refers to the deviation of the recorded value from the true value, due to any number of causes. Although it may be framed differently, measurement error is also the pursuit of accuracy. Measurement error is a longstanding topic of interest in survey research. Survey response errors may arise from the method of data collection, the survey respondent, or the survey itself. For example, the respondent may be dishonest, the interviewer poorly trained, or the survey ambiguously worded. These may all lead to measurement errors on the individual level, xiobserved , xitrue . The quality of a survey statistic θ̂n , or a point estimate in general, is often assessed by the mean squared error or MSE. The MSE is somewhat famously the sum of the squared bias and the variance, Eθ (θ̂n − θ)2 = (θ̄n − θ)2 + Eθ (θ̂n − θ̄n )2 .
Bias, the first term on the right hand side, is the constant error that arises from
We’ll explore and propose reference values in Section 6.1.
the survey design. Variance, the second term on the right hand side, measures the variable error. It arises from the particular implementations of the survey design (e.g. due to the specific set of respondents) (Groves, 2004).7 In economics, researchers have pursued measurement error with a particular interest in data revisions, as mentioned in Section 3.3. Often, economists want to use data as soon as it is released, even if it is expected to be revised. Rather than wait till the preliminary data is finalized, economists will sometimes nowcast: they forecast what the revised values will be using the already available data. This practice, of course, accepts the existence of measurement errors, ytrue − yij .8 Measurement errors are often modeled as noise, news, and spillovers. Noise is correlated with the data release and is orthogonal to the true value. These revision errors are generally able to be predicted. In this case, the release’s values are not the optimal nowcasts, because they are expected to be revised in a predictable fashion. News results from ”rational forecast errors.” In this condition, measurement errors are uncorrelated to previous releases. If a release contains pure news, revision errors are not able to be predicted. In this case the initial data release is the optimal nowcast. Spillovers are those measurement errors such that the restatement of one value may drive the restatement of nearby values. Spillovers improve forecasts of measurement errors (Jacobs and Norden, 2011). Without naming them, we already explored some of these topics in Chapter 3. Provisional changes may be modeled as noise (Figure 3.15). Some retroactive changes certainly contain news and spillovers (Figure 3.14). In that section we
Notation taken from Wasserman (2010). Although it would be lovely if they were, it is generally accepted that measurement errors are not ”well-behaved.” Researchers are often interested in the ability to forecast revision errors, yij − yij+1 .
set the ”truth” values, ytrue i , to be the values included in a particular release, as economists often do in practice (Jacobs and Norden, 2011).9
Completeness
Unlike accuracy, the definition of completeness has largely strayed form Wang and Strong, 1996’s early offering: ”the extent to which data are of sufficient breadth, depth, and scope for the task at hand.” Although Ardagna et al. (2018) refers to Wang and Strong (1996)’s definition, their application diverges. They assess completeness with a ratio of the number of available values to the number of expected values. This metric has practical shortcomings. For example, databases often suffer from duplicate entries which would quietly invalidate this metric. Ramasamy and Chowdhury (2020) takes a similar approach. Other approaches remove expectations and instead examine the data presented. Serhani et al. (2016) and definitions reviewed by Batini et al. (2009) focus on the existence of null values. Batini et al. (2009) note that a null value may appear because: 1) a value exists but is unknown, 2) a value does not exist, or 3) it is unknown whether a value exists. Null values are an omnipresent challenge for the big data practitioner. They are due more attention. In addition to its presence, Cai and Zhu (2015) consider the datum’s value. They define completeness in terms of whether a datum is both present and falls within the acceptable set of values. The definition given by Batini et al. (2009) bridges this approach with Wang and Strong (1996)’s. They define completeness
In the Section 6.1 we’ll introduce an alternative option.
as ”the degree to which a given data collection includes data describing the corresponding set of real-world objects.” Zaveri et al. (2015) tease apart these distinctions instead of combining them. They distinguish three types of completeness: schema completeness, column completeness, and population completeness.
Shortfalls in completeness could be characterized as errors of nonobservation. These occur when only a partial measurement or no measurement at all is recorded. According to survey sampling theory, errors of nonobservation arise from issues with coverage, nonreseponse, and sampling (Groves, 2004). With the advent of highly accessible big data, many practitioners have begun substituting the size of data for the statistical assurances of well-designed samples. Meng (2018) offers a critical, convincing, theoretically-backed, and politely scathing indictment of this practice. Providing practical examples, the author notes that many big data sets are ”self-Reported” or ”administratively Recorded.”10 In other words, in the world of big data it is common for a practitioner to treat a dataset as though it were a sample of a population that he or she would like to describe. But, these are not samples in the statistical sense. In general they do not arise from a well-designed sampling mechanism. These datasets generally have an underlying mechanism that produces them, which excludes and includes groups by design. Thus, nonobservation errors are likely to abound. To demonstrate the dangers, Meng proves that when the sampling mechanism for a large population is not tightly controlled the effective sample size shrinks shockingly quickly.
The conclusion is perhaps more obvious than an epiphany: if a big dataset is to be used as though it were a sample, it must be held to the same standards as a sample.11 Whether using big or small data, missingness is a powerful and prevalent concern. The statistical approach to missingness is unsurprisingly parameterized. The central parameter of interest is θi , the probability that yi is missing in the given dataset. Missingness is categorized into one of three types according to θi : missing completely at random (MCAR), missing at random (MAR), and not missing at random (NMAR). When the mechanism of missingness is blind to the dataset, that is θi is independent of y, it is said to be MCAR. If θi is independent of only missing values but dependent on the observed values, then the missingness is MAR. This may occur, for example, if women report their age less frequently than other respondents. Not missing at random, NMAR, is missingness that such that θi depends on the value that is missing. This is known as a nonignorable non-response. For example, if the unvaccinated report their number of inoculations less frequently than the vaccinated. It is no surprise that NMAR data is of greatest concern, followed by MAR, and lastly by MCAR (Arnab, 2017). It it NMAR that big datasets, when treated as though they are statistical samples, are likely to suffer.
Meng (2018) implicitly defines data quality as the ability of a data set to estimate a particular statistic for the intended population. This is not a common definition in the field of DQ, but it is a critical concept in the world of applied data science.
Consistency
Even the subject of consistency is not agreed upon. An early definition from Wang and Strong (1996) defines ”representational consistency” as the extent to which data are always presented in the same format and are compatible with previous data. On the other hand, Ramasamy and Chowdhury (2020) seek the absence of difference between multiple representations of the same thing. Cai and Zhu (2015) nod to this idea, referring to it instead as equivalency, but the authors do not use it themselves. Other authors define consistency across elements of a dataset. Cai and Zhu (2015) emphasize respecting logical relationships between datums. Batini et al. (2009), Serhani et al. (2016), and Juddoo (2015) value data that conform to constraints or rules. Karr, Sanil, and Banks (2005) incorporate both hard and soft constraints and plausible ones, viewing consistency from a perspective of intrarecord relationships. An example of such a constraint is that an arrival time must not be later than a departure. Abdullah et al. (2015) use integrity to refer to the maintenance of relationships among entities and attributes. Batini et al. (2009) nods to this standard as well, directing interested readers to database integrity discussions. As for Abdullah et al. (2015)’s definition of consistency, they introduce another divergence. They ask ”are data elements consistently defined and understood?”
Preliminary Data and Data Revisions
“Data revisions have haunted economists for decades.” Jacobs and Norden, 2011
The very existence of data revisions is antithetical to some definitions of consistency. And yet, data revisions exist–out of both necessity and design. A data revision occurs when a different value is reported for an observation for which a value had previously been reported. Sometimes this occurs by design, sometimes due to corrections, and sometimes due to the data production process or changes therein. Economists have battled data revisions long before big data introduced them at scale.12 Over the course of that struggle, they’ve come up with a variety of terms to describe the issue. For example, Trivellato and Rettore (1986) use the term preliminary data to refer to the initial data that will eventually be revised. The values, once settled, are called final. They also differentiate between current revisions and occasional revisions. The former being those restatements which are routine, expected, and introduced relatively soon after the initial release. The latter refers to unplanned revisions. These often arise from definition changes or delayed changes to the underlying data. Bordignon and Trivellato (1989) refers to the initial values as provisional data, hinting at the expectation of a low volume of changes. Many in econometrics, including McDonald et al. (2021), use vintage data to refer to previously published but no
Data discussed in relevant econometrics literature tends to be of dramatically different cadence and size than that which we are interested in. For example, Julio (2011) concerns itself with the quarterly Colombian gross domestic product (GDP) releases from 1995 through 2009. Jacobs and Norden (2011) refers to quarterly vintages of the Federal Reserve Bank of Philadelphia from 1965 through 2006, reporting on quarters from 1947 through 2006. In contrast, we are interested in datasets that report daily values for geographies across the United States that were updated multiple times daily over the course of for more than two years.
longer current datasets. This includes the history of a dataset up to the point of analysis. McDonald et al. (2021) emphasize the need to use vintage data when training models to avoid overly optimistic performance estimates. Training a model on finalized data is, in effect, training a model with data that you could only get if you had the ability to see the future.13 This foundation is helpful, but not sufficient for our discussion of the ongoing evolution of data. Instead, we’ll look to the world of software for help. We prefer to view data as versions or releases. This aligns more closely with the practice of version control within software development. It also emphasizes the expectation that data will indeed change and that data is not necessarily compatible across versions. Data revisions balance the competing interests of accuracy and timeliness, with little concern for consistency. They are perhaps the most forthright demonstration of the very real and very unromanticized realities of data production. Restatements are central to this body of work because they are central to our honest understanding of the quality of data and how to use data properly.
Timeliness
“Outdated data can be worse than no data…they may create a false certitude.” Karr, Sanil, and Banks, 2005
Researchers largely agree that for data to be high quality it is essential that it be timely. What timely means, on the other hand, is not greed upon.
This is a particular, often overlooked, type of data leakage.
Some emphasize time with respect to the users’ need, such as Wang and Strong (1996): ”the extent to which the age of the data is appropriate for the task at hand.” Zaveri et al. (2015) focuses explicitly on the user’s requirement for updated data. Cai and Zhu (2015) breaks down the data timeline into generation, acquisition and utilization. Other authors define timeliness with respect to currency and volatility, like Serhani et al. (2016), Hartig and Zhao (2009), and Ballou et al. (1998). Ballou et al. (1998) defines currency as the age of the underlying datums from which information is produced. They describe volatility as the length of time that a datum remains usable. Timeliness is defined as a function of currency and volatility Currency = (DeliveryT ime − InputT ime) + Age
Volatility = ExpiryT ime − InputT ime + Age
where s is the shelf-life parameter that allows us to control for highly volatile data (large, e.g. s = 2) or low volatility data (small, e.g. s = .5). If the data was delivered while it was still useful (Currency < Volatility, i.e. DeliveryT ime < ExpiryT ime), then T imeliness > 0. If, on the other hand, it took longer to deliver than the data could have been useful (Currency > Volatility, i.e. DeliveryT ime > ExpiryT ime), then T imeliness = 0.14 Volatility is intrinsic to the data15 and independent of the production process. For example, a highly volatile stock price is volatile regardless of what system records it. Currency, on the other hand, is a property of the data production process. For example, how long ago a stock price was reported is dependent on the
data production process (Ballou et al., 1998). Despite these distinctions, Batini et al. (2009) note that currency and timeliness are often used interchangeably in practice.
Validity, Believability, and Credibility
Some authors like, Ramasamy and Chowdhury (2020), present validity as closely adjacent to the rules-based consistency definitions of Batini et al. (2009), Serhani et al. (2016), and Juddoo (2015). Others define validity similarly to the domain definitions of accuracy. Karr, Sanil, and Banks (2005) actually states that ”validity is a weakened but more readily measured form of accuracy.” Karr, Sanil, and Banks (2005) describe a value to be valid if it falls in ”some exogenously defined and domainknowledge dependent set of values.” Abdullah et al. (2015) mostly aligns with this definition. As Karr, Sanil, and Banks (2005) note, data can be valid and not accurate, but not vice-versa. In the realm of trusted-not-tested, Wang and Strong, 1996 define believability as the extent to which data are accepted or regarded as true, real, or credible. Essentially, they are refering to the reputation of the data. Cai and Zhu (2015) defines credibility as essentially ”believability” for non-numeric data.
A change point indicates ”a transition between different states in a process that generates the time series data”(Aminikhanghahi and Cook, 2017). Change point
detection is the effort to identify such changes within time series. A breadth of both supervised and unsupervised algorithms have been applied to the problem. The real-world need to detect changes is often a real-time problem. As such, ”online” solutions have proliferated alongside ”offline”, or batch, algorithms. In contrast, online, or real-time, algorithms run concurrently with the process they are monitoring, processing each data point as it becomes available, with a goal of detecting a change point as soon as possible after it occurs, ideally before the next data point arrives (Aminikhanghahi and Cook, 2017). In terms of data quality, a change point could indicate a change in the underlying data production process, a change in definition, an error, or a correction. Of course, a detected change point might not indicate a DQ issue at all. It may indicate a completely accurate recording of a real change in the measured reality. Like the ones discussed in Chapter 3, both true surges and non-retroactive changes may be detected as change points (or not).
Other Dimensions
It would be impractical and superfluous to attempt to include all proposed dimensions and their varying definitions. Ramasamy and Chowdhury (2020) provides an easily digestible summary of the dimensions included in a number of works, of which Figure 4.1 is a selection. A few interesting ones are variety of data and data sources, appropriate amount of data, volume, confidentiality, and value-added. Although their work does not focus on DQ, George et al. (2016) raise two ”elements of data science” that are worth discussing with respect to data qual-
ity. The first is data scope, described as ”the comprehensiveness of data by which a phenomenon can be examined.” Their description lies somewhere between Wang and Strong (1996)’s relevancy and completeness. The second is granularity. They define it as ”direct measurement of constituent characteristics of a construct rather than distal inferences from data.” They give the example of bio-metric readings as opposed to survey responses. In practice, granularity usually refers to the unit at which data is measured, e.g. country-level versus state-level. In the daily life of a data scientist, it is one of the first hurdles to clear when evaluating whether or not data is fit for use. Interoperability, or the ability for a data set to be used in conjunction with others, is another noteworthy consideration. The concept is not completely excluded from DQ literature, but it is a major area of concern in health care (Queen and Manocchio, 2022; Council of State and Territorial Epidemiologists (CSTE), 2019). Beyond health care, interoperability is a prominent quotidian concern for practicing data scientists.
Measurements
As Hartig and Zhao (2009) and others note, existing research offers few examples of specific quantitative measurements of data quality. Karr, Sanil, and Banks (2005) posit that only a select few dimensions are quantifiable but most authors refer to quantification of the dimensions broadly. Zaveri et al. (2015) label metrics as either quantitative or qualitative, though they do not present formulas for the quantitative metrics. Batini et al. (2009) provide definitions (but not formulas) for metrics associated with the dimensions, providing a clearer
Figure 4.6 (adapted). An Example of Concrete Formulas in DQ Literature Although imperfect, this table from Serhani et al. (2016) is a rare example of DQ metrics. Like so much else in the field, equations for the first three dimensions do not quite align with those we’ve already reviewed.
| Metric | Formula | Description |
|---|---|---|
| Timeliness | ||
| TMa | 1 − CMa / VMb | 1 − Currency/Volatility |
| TMb | numOfProcessedRecs / totalRecs / timePeriod | Percentage of the completed processed records within a time limit |
| Currency | ||
| CMa | currentTime − updateTime | Time of update |
| CMb | updateTime − storageTime | Difference between time of update and time of storage |
| Volatility | ||
| VMa | ConstantTimePeriodValue | Time length for which data remains valid |
| VMb | (storageTime − updateTime) / totalTime | Volatility: (time of data − time of update)/total time |
| Accuracy | ||
| AMa | numOfCorrectValues / totalValues | The ratio between the number of correct values stored and the total number of values |
| AMb | AvgUsrResponse | User questionnaire |
| Completeness | ||
| CMPMa | numOfEmptyValues / totalValues | The ratio of the number of empty or null values over the total number of values |
| CMPMb | AvgUsrResponse | User questionnaire |
| CMPMc | actualTotalSize / expectedTotalSize | The total size of the stored records over the expected size of the data |
| Consistency | ||
| CNSMa | numOfInconsistentValues / totalValues | The ratio of the total number of inconsistent values over the total number of values |
| CNSMb | numOfViolations | The total number of values violating constraints and rules |
view if not a precise one. Ballou et al. (1998)’s timeliness metric, Equation 4.4.4, and associated currency metric, Equation 4.4.2, are referenced by a number of papers, likely because there are few other metrics to reference. Serhani et al. (2016) leans on Ballou et al. (1998) when presenting their table of metrics, Figure 4.6. Although flawed and in places at odds with other literature, we include this table as a rare example of proposed formulas for metrics beyond timeliness. Pipino, Lee, and Wang (2002) do not provide explicit metrics, but they present ”functional forms” from which to build data quality metrics.
• Simple Ratio 1 − UndesiredOutcomes for dimensions like completeness and conT otalOutcomes sistency • Min or Max Operation[sic] for dimensions like timeliness and believability (after a subjective assessment has been gathered) • Weighted Average in the ”multivariate case.”16
Some authors imply or propose a search for a single data quality measurement. Hartig and Zhao (2009) view data quality as an aggregation of multiple sub-criteria. Pipino, Lee, and Wang (2002) recommend combining subjective and objective data quality assessments.
Management, Assessments, and Methodologies
By now it should be no surprise that there is not yet a standard management framework for big data quality (Taleb, Serhani, and Dssouli, 2018). There is no
shortage of proposals, though.17 Some research seems far removed from practical application. Taleb, Serhani, and Dssouli (2018) present idealized data quality management frameworks in which data quality could be reported at every stage of data production, processing, and use. Serhani et al. (2016) also holds very high hopes for DQ in practice, asserting ”quality should be addressed across the value chain at each single activity, data, and phase.” Other work is utterly practical. Wijnhoven et al. (2007) present a process and team design for managing data quality and improvement. In their case study, they note competing priorities of team members, early departure from meetings, and the challenges of scheduling during the holidays. A few steps more removed from corporate life, Ardagna et al. (2018) investigate optimizing data quality evaluation under the constraints of time and budget. Abdullah et al. (2015) presents a team structure and a process for managing data quality, although it remains very high level and does not include an application. Higher level still, Kahn, Strong, and Wang (2002) build their framework of data around the dual views of data as a product and as a service (Figure 4.3).
Further Work Needed
It is clear that the dimensions of data quality are still up for debate, as are the definitions of those dimensions. However, as many have noted, DQ should not be ”one size fits all.” Data quality must be understood as result of the data’s particular data production process. Data quality must be defined in the context of the particular study, application, or ”task at hand” (Wang and Strong, 1996; Meng, 2018; Pipino, Lee, and Wang, 2002). Additionally, DQ dimensions must also be understood in the context of each other. Dimensions are not independent (Zaveri et al., 2015), as we’ve discussed with timeliness and accuracy. Succeeding in one dimension often comes at the cost of another. These trade-offs are being made, explicitly or implicitly, with every dataset that’s produced. It’s time we start considering how best to do so. Finally, data quality must be understood in the context of the data itself. The volume, variety, and velocity of big data bring new and important challenges to data quality. Big data often does not meet the requirements statisticians and other data practitioners have set for data (Meng, 2018). And yet, we should not ignore such big data. Instead, we should understand the data itself and its quality–and act in light of that information.
Notes
-
As the authors note, that followed the standard within contemporary literature on the topic.
-
Even then, the data is sometimes unconscionably artificial. For example, exploring completeness within a dataset whose elements are removed according to a uniform distribution, embodying the utopian ideal of missing completely at random.
-
Emphasis is not my own.
-
Equations 4.4.2 and 4.4.4 are taken from Ballou et al., 1998, equation 4.4.3 is taken from Hartig and Zhao (2009).
-
Implicitly, this assumes volatility is also dependent on the use case.
-
To this author’s best understanding, the “multivariate case” refers to a single dimension assessed on multiple examples, e.g. columns.
-
For a systematic comparison of data quality assessment and improvement methodologies, see Batini et al. (2009).